1. 서비스 거부 공격 (DoS, Denial Of Service)
컴퓨터의 자원을 고갈시키기 위한 공격으로, 특정 서비스를 계속 호출하여 CPU, Memory, Network 등의 자원을 고갈시키는 공격이다.
DDoS(Distributed DoS)는 여러대의 공격자 서버가 분산되어 있고 특정 시스템을 집중적으로 공격하는 방법이다.
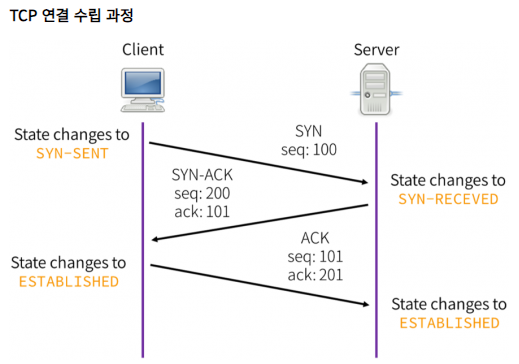
1) TCP SYN Flooding
- TCP SYN을 이용한 공격 방법으로, 대상 시스템이 Flooding하게 만들어 대상 시스템의 서비스를 중단시키는 공격
- 다른 사용자가 서비스를 받지 못하도록 하는 공격
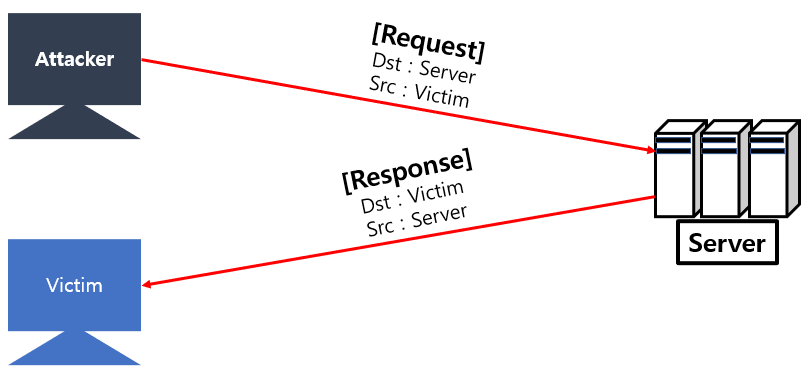
Cf) DRDoS(Distributed Reflection Denial os Service)
- IP Header에 들어가는 Src IP를 공격자의 IP가 아닌 피해자의 IP 주소를 기재하여 Request 전송
- Dst 서버는 피해자의 IP로 응답을 하게되는데, 이 작업을 반복하려 피해자에게 DoS 공격을 수행
2) ICMP Flooding(Smurfing Attack)
- 다수의 호스트가 존재하는 네트워크상에서 ICMP Echo 패킷을 Broadcast로 전송
- Src IP는 피해자의 IP주소를 기재하여 전송
- 다량의 응답 패킷이 피해자 서버로 집중되게하여 서비스 장애 유발
3) Tear Drop(Ping of Death)
- 네트워크 패킷은 MTU보다 큰 패킷이 오면 분할하고, 분할된 정보를 flags와 offset이 가지게 됨
- offset을 임의로 조작하여 다시 조립될 수 없도록 하는 공격
- Fragment를 조작하여 패킷 필터링 장비나 IDS를 우회하여 서비스 거부 유발
4) Land Attack
- IP Header를 변조하여 인위적으로 Src IP를 Dst IP 주소와 Port로 설정하여 트래픽을 전송
- 송신자와 수신자의 IP, Port가 동일하기 때문에 네트워크 장비의 부하 유발
- 대응 방법: 송신자와 수신자의 IP가 동일한 패킷을 삭제

5) HTTP Get Flooding
- 3 way handshaking 이후 HTTP Get을 지속적으로 요청하여 HTTP 연결 및 HTTP 처리 로직까지 과부하 유발
- TCP 3 way handshaking 이후 공격을 수행하기 때문에 IP를 변조하지 않음
Cf) slow HTTP Get Flooding
- HTTP Header를 변조하여 Content Length 값을 50,000으로 변경 후 1바이트씩 천천히 전송
- 웹 서버는 50,000 값이 수신되기를 대기하게되고 더 많은 부하가 발생
- 'slow'가 붙은 공격들은 위처럼 무언가를 천천히 전송해서 웹 서버에 더 많은 부하를 유발하는 공격
6) Cache Control Attack
- 자주 변경되는 데이터에 대해서 새롭게 HTTP 요청과 응답을 요구하는 옵션인 'no-cache'를 설정
- Cache-Control을 'no-cache'로 설정하고 웹 서버를 호출하면 항상 최신 페이지를 전송해주어야 하기 때문에 서버는 더 많은 부하가 발생
7) Slow HTTP Get/Post Attack
[Slow HTTP Get]
- TCP 및 UDP 기반 공격: 변조 IP가 아닌 정상 IP 기반 공격이며, 탐지가 어려움
- 소량의 트래픽을 사용한 공격: 소량의 트래픽과 세션 연결을 통해서 공격
- 애플리케이션 대상: 서비스의 취약점을 이용한 공격
[Slow HTTP Post]
- HTTP의 Post를 사용하여 서버에게 전달할 대량의 데이터를 장시간에 걸쳐 분할 전송
- Post 데이터가 모두 수신되지 않으면 연결을 장시간 유지하게 됨

[Slow HTTP Read DoS]
- TCP 윈도우 크기 및 데이터 처리율을 감소시킨 뒤 데이터 전송하여 웹서버가 정상적으로 응답하지 못하도록 하는 공격 (ex. TCP 윈도우 크기를 0byte로 만들어 전송)
- TCP 윈도우 크기 및 데이터 처리율을 감소시키면 서버는 정상 상태로 회복될 때까지 대기상태에 빠지게 됨
- 서버는 윈도우 크기가 0byte인 것을 확인하면 데이터를 전송하지 않고 Pending 상태로 전환됨
- 공격자는 윈도우 크기를 점검하는 Probe 패킷에 대해 ACK로 전송하면 서버는 대기 상태로 빠지게 됨

[Slow HTTP Header DoS(Slowloris)]
- HTTP Header를 비정상적으로 조작해서 웹 서버가 HTTP Header 정보가 모두 전달되지 않은 것으로 판단하게 함
- 웹 서버는 클라이언트로부터 요청이 끝나지 않은 것으로 판단하여 연결을 장시간 유지
- HTTP Header와 Body는 개행문자(\r\n\r\n)로 구분되는데, \r\n만 전송하여 불완전한 Header를 전송
2. Port Scanning
포트 스캐닝은 서버에 열려있는 포트를 확인하기 위한 방법이며, 공격자는 이를 악용하여 확인된 포트의 취약점을 이용하여 공격할 수 있다.
- NMAP Port Scanning
| NMAP Port Scan | 설명 |
| TCP connect() Scan | - 3-Way Handshaking을 수립하고, Target System에서 쉽게 탐지 가능 |
| TCP SYN Scan | - SYN을 전송하여 SYN/ACK 패킷을 수신하면 Open 상태 - SYN을 전송하여 RST/ACK 패킷을 수신하면 Close 상태 - Half Open 또는 Stealth Scanning 이라고 함 (로그가 남지 않음) |
| TCP FIN Scan | - FIN 패킷을 전송했을 때, 닫혀있는 포트는 RST를 전송 - 열려있는 포트는 패킷을 무시 |
| TCP Null | - 모든 플래그를 지움 - 대상 포트가 닫혀있으면 RST를 전송하고, 개방 상태이면 패킷을 무시 |
| TCP X-MAS Tree Scan | - FIN, URG, PSH 패킷을 전송 - 대상 포트가 닫혀있으면 RST를 전송하고, 개방 상태이면 패킷을 무시 |
| TCP Open Scan | - TCP 3-way-handshaking 과정을 진행하여 오픈된 포트 확인 - 서버에 로그가 기록되고 스캔 속도가 느림 |
| UDP Scan | - UDP Packet을 전송하여 스캐닝하며, UDP의 특성상 신뢰성이 떨어짐 - 대상 포트가 닫혀있으면 ICMP Unreachable, 개방 상태이면 패킷을 무시 |
3. Sniffing Attack
네트워크로 전송되는 패킷을 훔쳐보는 도구로, 송신자와 수신자의 IP, Port, Message 등 확인이 가능하다.
스니핑 도구를 실행시키면 기본적으로 Normal Mode로 실행되며, Normal Mode는 자신의 컴퓨터에 전송되는 패킷만 수신받고 관계없는 패킷은 삭제한다. 네트워크에 흘러다니는 모든 패킷을 모니터링 할 때는 Promiscuous Mode로 설정해야 한다.
Cf) Session Hijacking
- 세션값을 훔쳐(세션값을 획득하여) 로그인 과정 없이 홈페이지에 접근할 수 있음
- 이미 인증을 받아 세션을 생성, 유지하고 있는 연결을 빼앗는 공격
- 인증을 위한 모든 검증을 우회: TCP를 이용해서 통신하고 있을 때 RST 패킷을 보내 일시적으로 TCP 세션을 끊고 Sequence Number를 새로 생성하여 세션을 빼앗고 인증을 회피
- 원인: 암호화되지 않은 프로토콜에서 정보를 평문으로 전송, 길이가 짧은 Session ID, Session Timeout 부재
4. Spoofing Attack
1) IP Spoofing
- 자신의 IP를 속이는 행위로, 공격자가 자신의 IP주소를 숨기거나 피해자의 IP로 가장하여 접속하는 방법
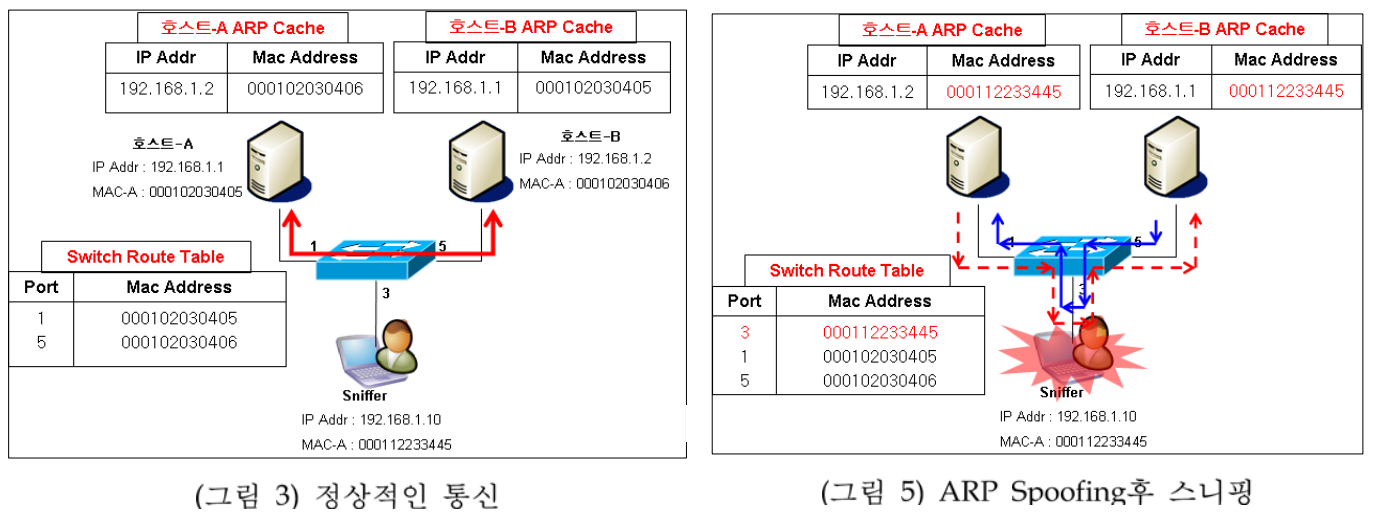
2) ARP Spoofing
- 로컬 통신 과정에서 서버와 클라이언트가 IP와 MAC 주소로 통신하는 것을 이용
- 클라이언트의 MAC Addr를 중간에 공격자가 자신의 MAC Addr로 변조하여 마치 서버와 클라이언트가 통신하는 것처럼 속이는 공격
# 참고
해당 글은 '이기적 정보보안기사 필기 1권 이론서'을 읽으며 필요한 부분만 정리한 내용입니다.
'자격증 > 정보보안기사(필기)' 카테고리의 다른 글
| 정보보안기사(필기) - 애플리케이션 보안(인터넷 응용 보안) (0) | 2021.07.30 |
|---|---|
| 정보보안기사(필기) - 네트워크 보안(네트워크 대응 기술) (0) | 2021.07.30 |
| 정보보안기사(필기) - 네트워크 보안(네트워크 기초) (0) | 2021.07.22 |
| 정보보안기사(필기) - 시스템 보안(윈도우) (0) | 2021.07.21 |
| 정보보안기사(필기) - 시스템 보안(리눅스) (0) | 2021.07.20 |